publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
★ denotes a first-authored paper. * denotes co-first authorship.
2026
-
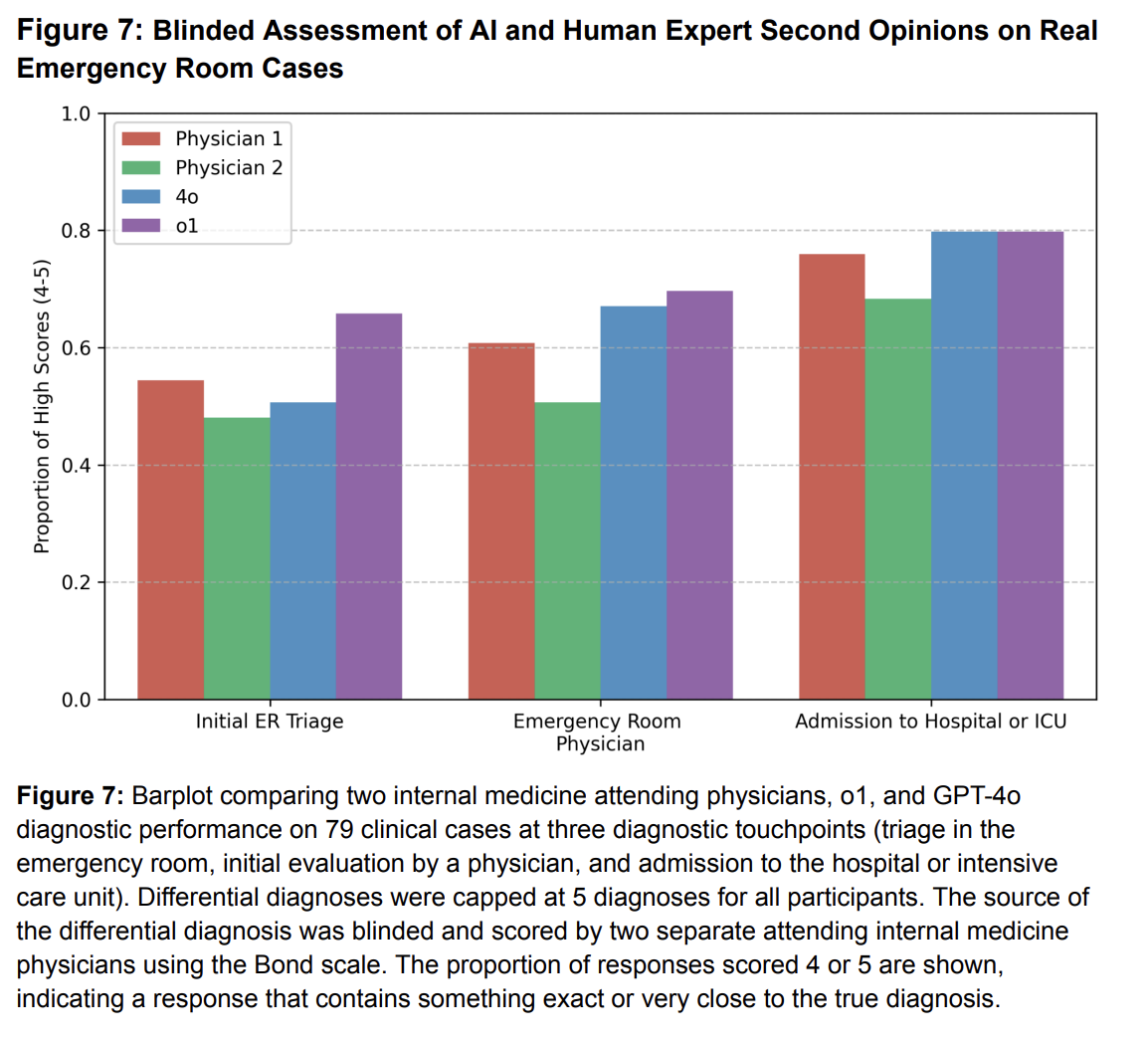 Science
ScienceAcross six clinical reasoning tasks — including an experiment using real cases from the Beth Israel Deaconess Medical Center emergency department — a reasoning model (OpenAI o1) matched or exceeded a large panel of attending physicians. The result suggests that LLMs are saturating current clinical-reasoning benchmarks, motivating the need for prospective trials.
Science, Apr 2026 -
 NEJMNew England Journal of Medicine, Mar 2026
NEJMNew England Journal of Medicine, Mar 2026 -

2025
-
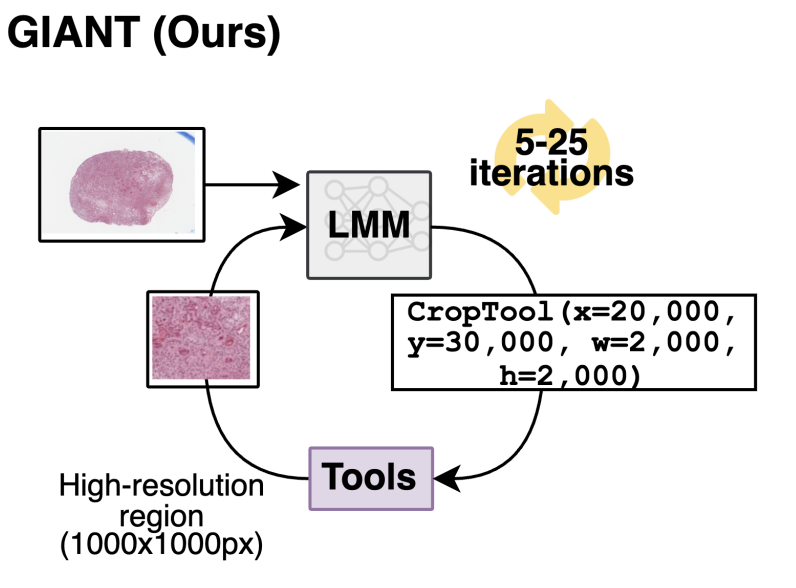 arXiv
arXivWe develop a simple algorithmic approach called GIANT that allows a multimodal LLM to navigate gigapixel pathology images. With GIANT, GPT-5 outperforms specialist pathology vision-language models.
arXiv preprint arXiv:2511.19652, Nov 2025 -
 NEJM
NEJMOur AI system, Dr. CaBot, generated the differential diagnosis for this challenging clinical case — the first AI-authored diagnosis published in an NEJM Clinicopathological Conference.
New England Journal of Medicine, Oct 2025 -
 arXiv
arXivDr. CaBot is an agentic AI system that emulates an expert diagnostician, generating written and slide-based presentations from the case description alone; in blinded evaluations, physicians could not distinguish CaBot’s differentials from those by human experts in 74% of trials. We also introduce CPC-Bench, a physician-validated benchmark of 7,102 NEJM Clinicopathological Conferences (1923–2025) and 47,648 questions across 10 reasoning tasks, on which CaBot outperforms frontier models. Both are publicly available at cpcbench.com.
arXiv preprint arXiv:2509.12194, Sep 2025 -
 NEJM AINEJM AI, Sep 2025
NEJM AINEJM AI, Sep 2025 -
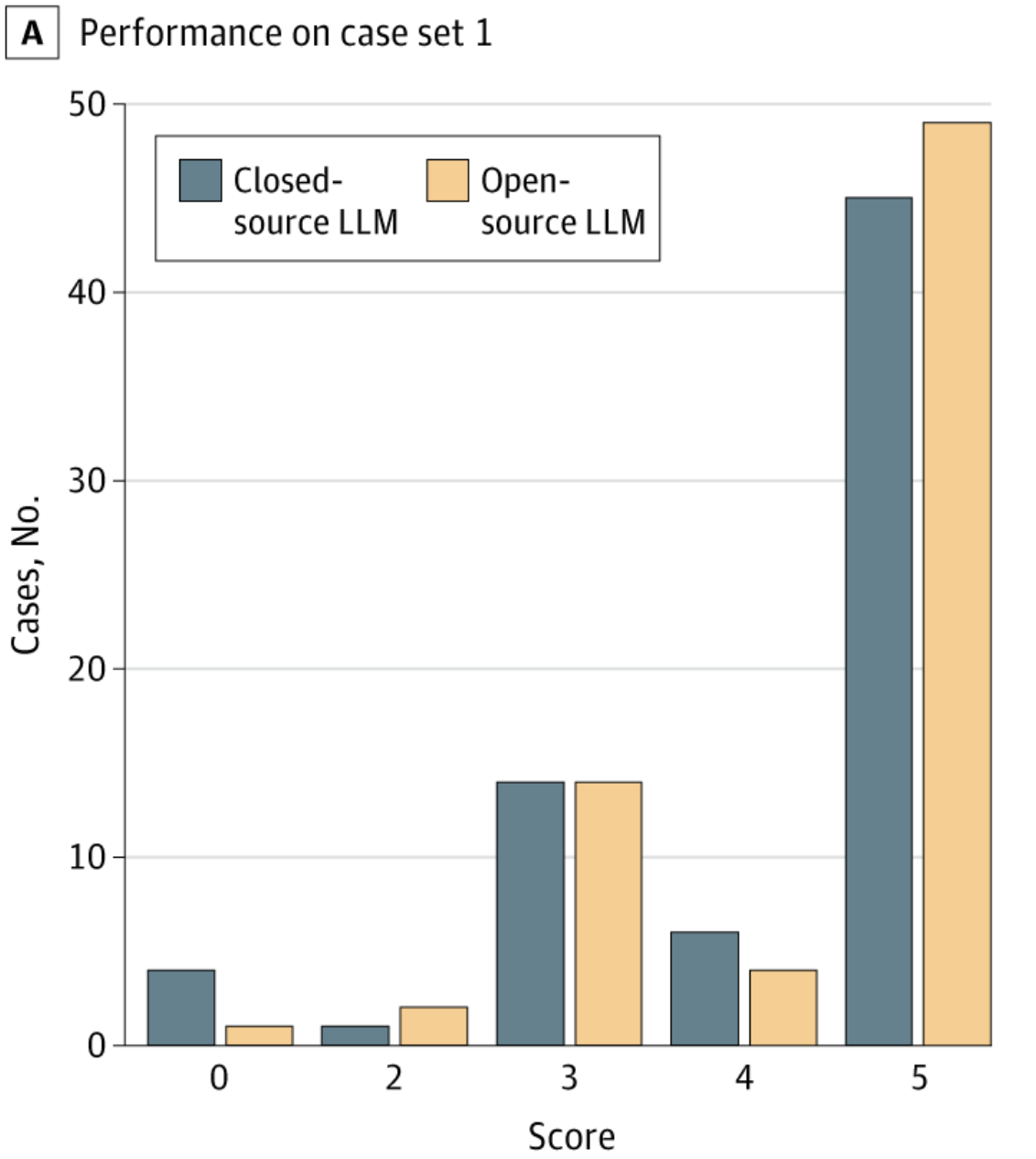 JAMA HF
JAMA HFOn NEJM clinicopathological cases, an open-source LLM (Llama 3.1 405B) matched or exceeded GPT-4 on diagnostic accuracy, suggesting that open-source models can compete with frontier proprietary systems on complex diagnostic reasoning.
JAMA Health Forum, Mar 2025
2024
-
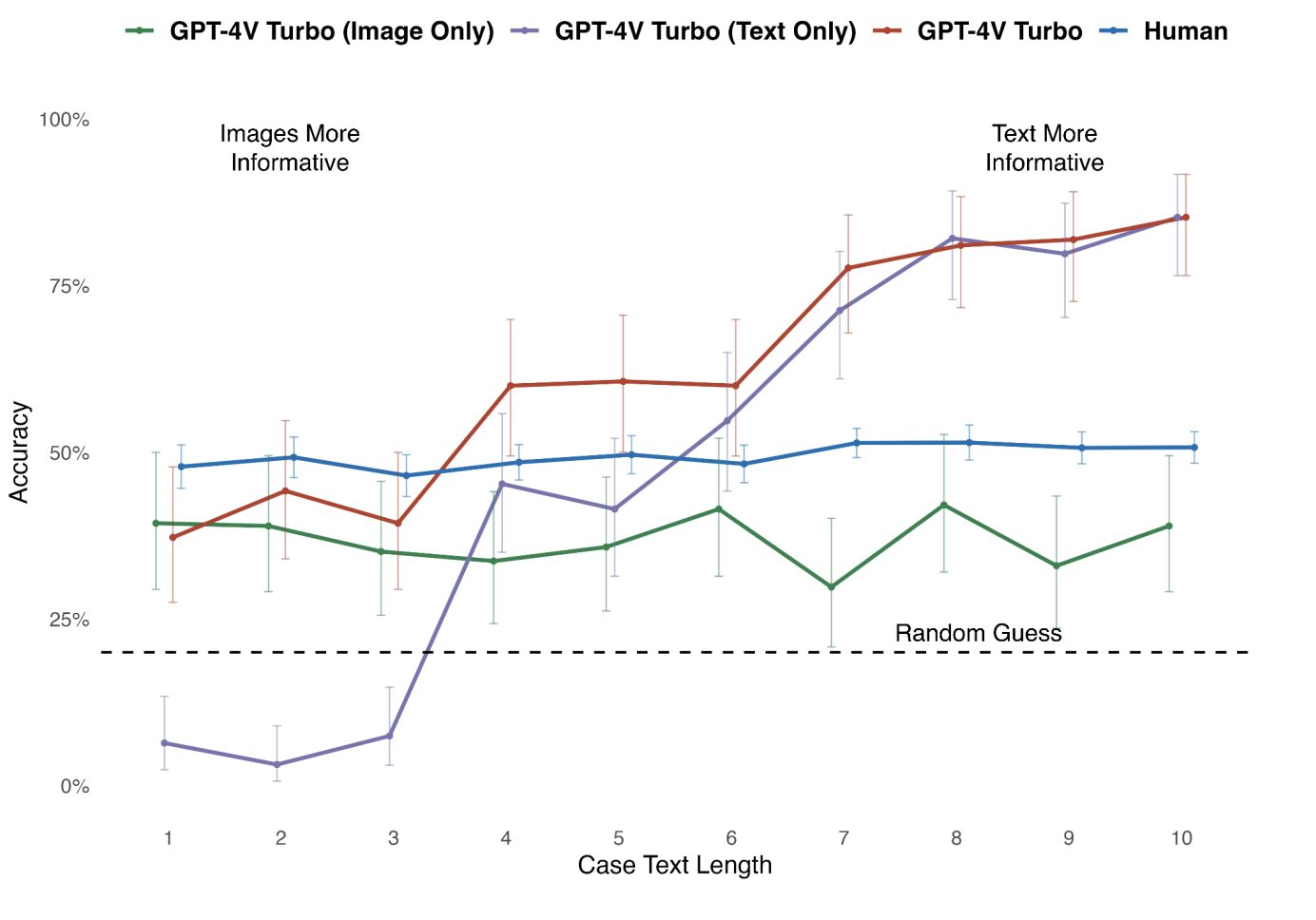 arXiv
arXivOn benchmarks that pair an image with accompanying clinical text, multimodal foundation models score well primarily by leveraging the text rather than analyzing the image.
arXiv preprint arXiv:2311.05591, Nov 2024

2023
-
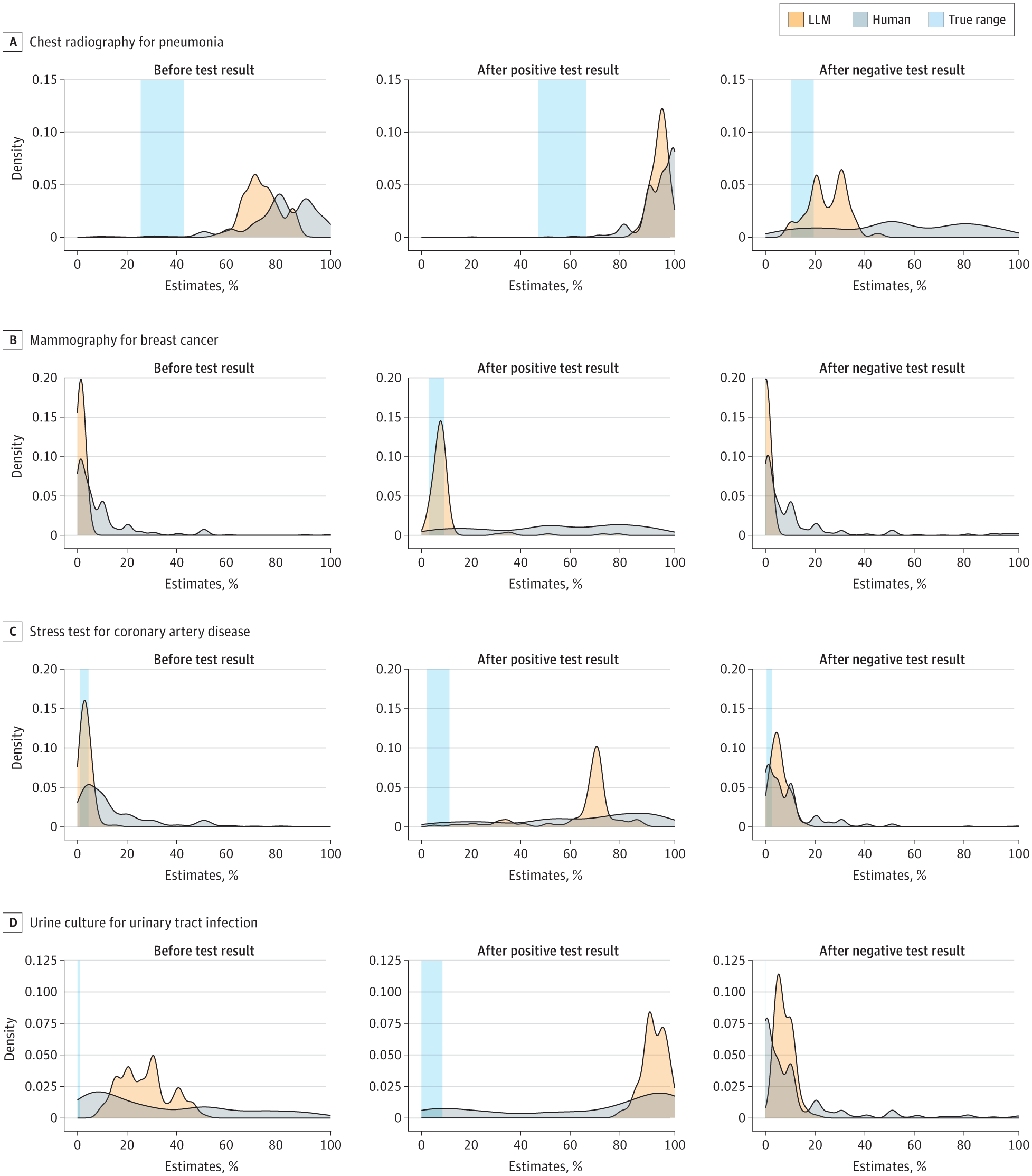 JAMA NO
JAMA NOCompared to a large baseline of physicians, LLMs accurately estimate pretest probabilities of diagnoses and update these estimates given new test results.
JAMA Network Open, Dec 2023