Thomas A. Buckley
PhD Student @ Harvard University

thomas_buckley [at] hms [dot] harvard [dot] edu
I am a PhD student in the inaugural AI in Medicine Program, advised by Prof. Arjun Manrai. My PhD is supported by the inaugural Dunleavy Fellowship for Clinical AI.
Large language models can now produce accurate diagnoses, but their role in real clinical care remains incompletely understood. My goal is to develop AI systems that integrate multimodal data, clinical evidence, and longitudinal patient context to serve as diagnostic second opinions at the bedside.
My first-author work has appeared in Science, the New England Journal of Medicine (NEJM), and other venues. An AI system I developed generated the first AI-authored diagnosis published in the 100-year history of the NEJM Clinicopathological Conferences. My work on AI diagnosis has been covered by The New Yorker and named one of Harvard Medical School’s Top 10 Stories of 2025.
Before Harvard, I earned a B.S. in Computer Science and a B.S. in Electrical Engineering from the University of Massachusetts Amherst, where I conducted research in the BINDS Lab with Prof. Edward Rietman and Hava Siegelmann. I am a 2-time alumnus of the Dr. Susanne E. Churchill Summer Institute in Biomedical Informatics (SIBMI) at Harvard, where I now serve as sole Teaching Fellow for the annual cohort (Summer 2025 and 2026). I am an affiliate of ARISE, a Stanford–Harvard research collaborative on AI in medicine.
In my free time, I enjoy tennis 🎾 and cooking 👨🍳.
news
| Apr 30, 2026 | Our paper evaluating LLMs across six clinical reasoning tasks was published in Science. Coverage in The Guardian, NPR, Harvard Magazine, and Harvard Medical School. |
|---|---|
| Mar 25, 2026 | Our reply about Dr. CaBot was published in the New England Journal of Medicine. |
| Dec 22, 2025 | Dr. CaBot was named one of Harvard Medical School’s Top 10 Stories of 2025. |
| Oct 08, 2025 | Harvard Medicine covered our AI-generated diagnosis published in the New England Journal of Medicine: AI System with Detailed Diagnostic Reasoning Makes Its Case. |
| Sep 29, 2025 | Dr. CaBot featured in The New Yorker: If AI Can Diagnose Patients, What Are Doctors For? |
| Sep 15, 2025 | Launched CPCBench, the public website for CPC-Bench, a large-scale benchmark based on the NEJM CPCs, and Dr. CaBot. |
| Apr 04, 2025 | Interviewed on the JAMA+ AI Podcast about our paper showing that open-source LLMs can now compete with closed-source models in diagnostic reasoning. |
selected publications
★ denotes a first-authored paper. * denotes co-first authorship.
-
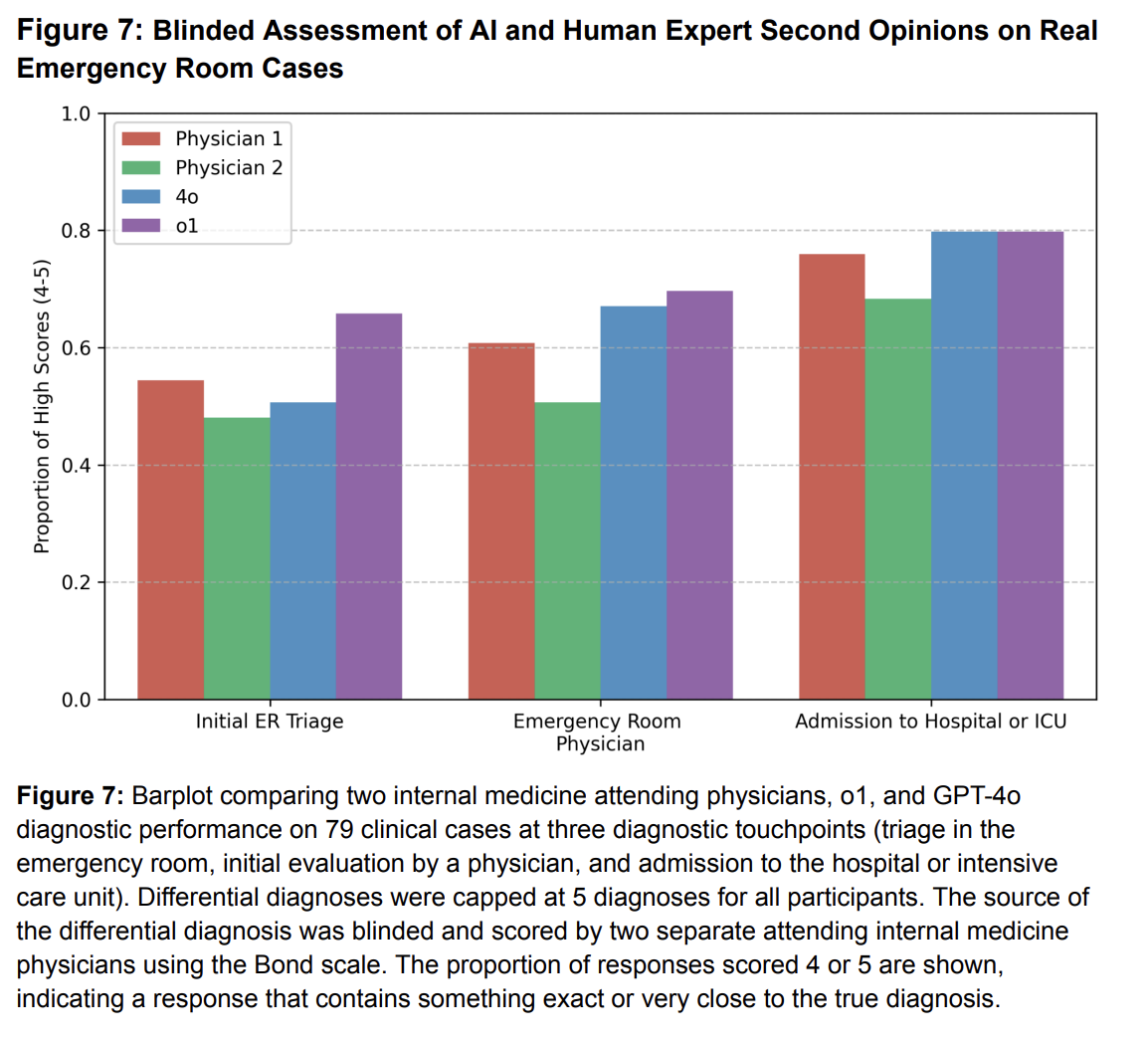 Science
ScienceAcross six clinical reasoning tasks — including an experiment using real cases from the Beth Israel Deaconess Medical Center emergency department — a reasoning model (OpenAI o1) matched or exceeded a large panel of attending physicians. The result suggests that LLMs are saturating current clinical-reasoning benchmarks, motivating the need for prospective trials.
Science, Apr 2026 -
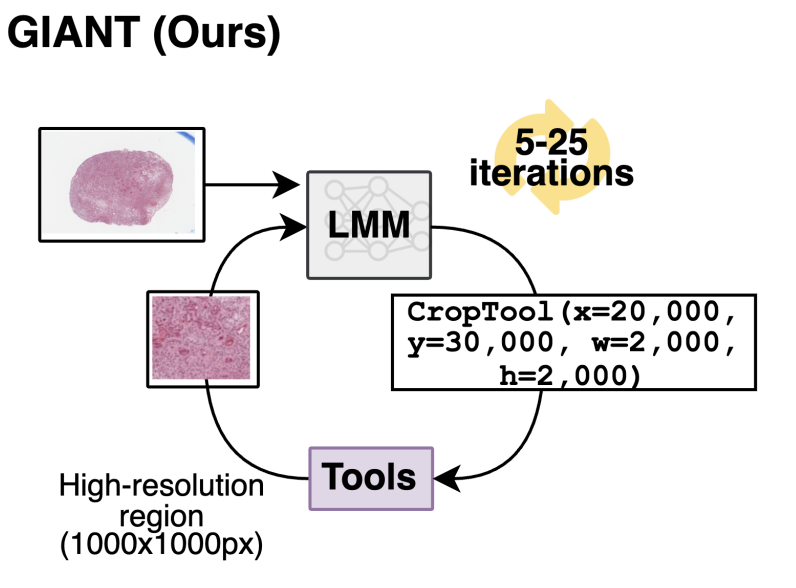 arXiv
arXivWe develop a simple algorithmic approach called GIANT that allows a multimodal LLM to navigate gigapixel pathology images. With GIANT, GPT-5 outperforms specialist pathology vision-language models.
arXiv preprint arXiv:2511.19652, Nov 2025 -
 NEJM
NEJMOur AI system, Dr. CaBot, generated the differential diagnosis for this challenging clinical case — the first AI-authored diagnosis published in an NEJM Clinicopathological Conference.
New England Journal of Medicine, Oct 2025 -
 arXiv
arXivDr. CaBot is an agentic AI system that emulates an expert diagnostician, generating written and slide-based presentations from the case description alone; in blinded evaluations, physicians could not distinguish CaBot’s differentials from those by human experts in 74% of trials. We also introduce CPC-Bench, a physician-validated benchmark of 7,102 NEJM Clinicopathological Conferences (1923–2025) and 47,648 questions across 10 reasoning tasks, on which CaBot outperforms frontier models. Both are publicly available at cpcbench.com.
arXiv preprint arXiv:2509.12194, Sep 2025 -
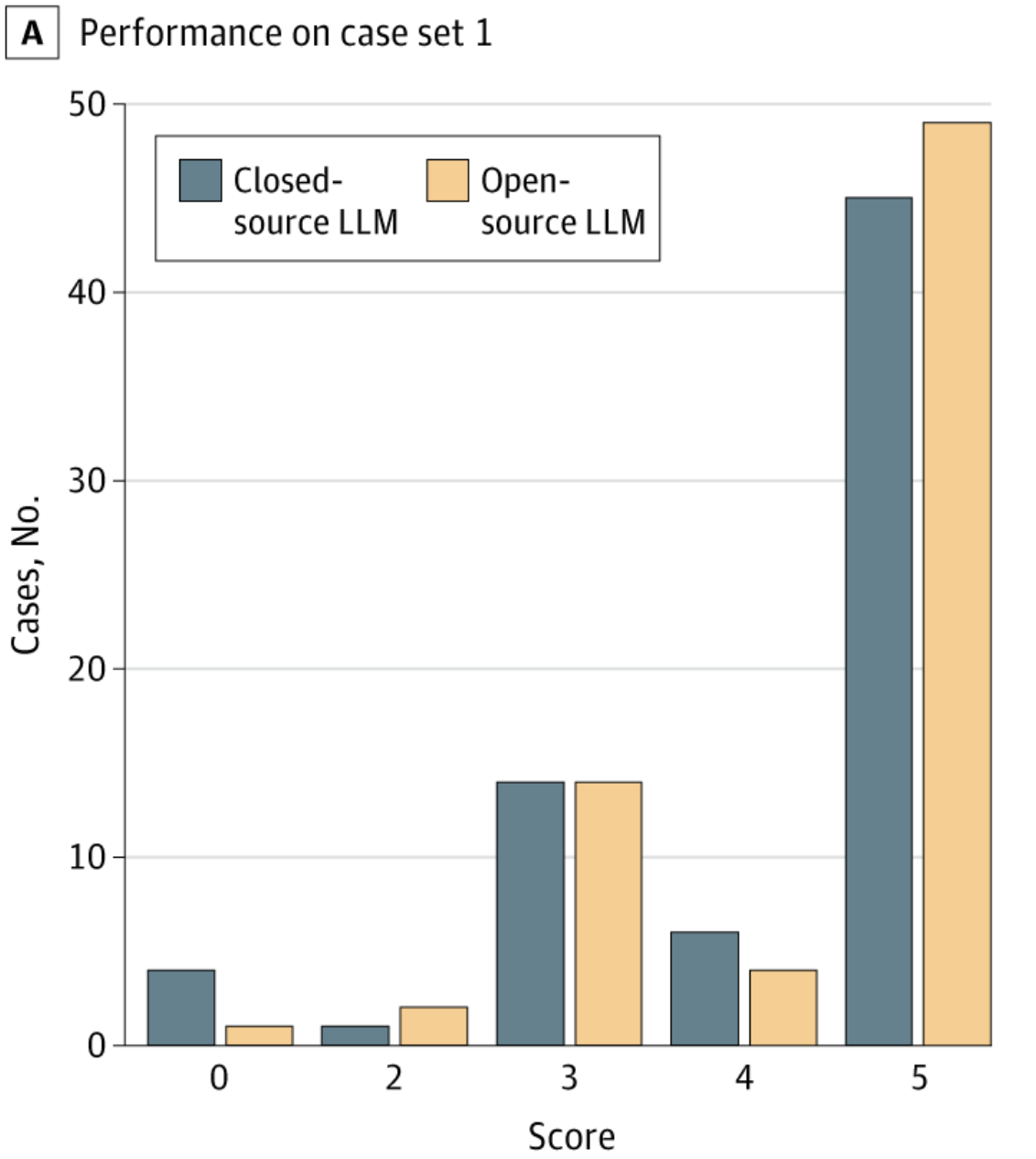 JAMA HF
JAMA HFOn NEJM clinicopathological cases, an open-source LLM (Llama 3.1 405B) matched or exceeded GPT-4 on diagnostic accuracy, suggesting that open-source models can compete with frontier proprietary systems on complex diagnostic reasoning.
JAMA Health Forum, Mar 2025 -
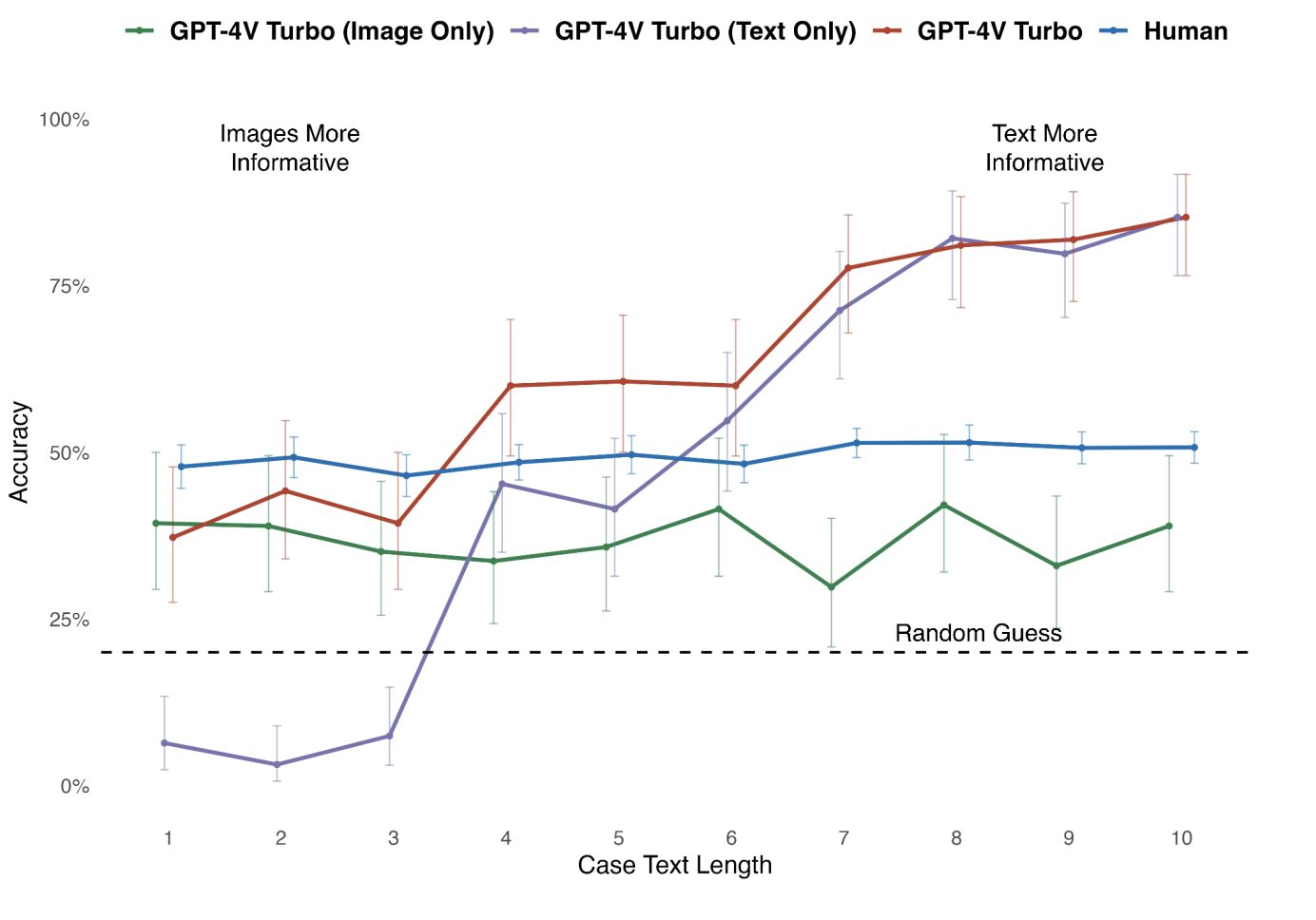 arXiv
arXivOn benchmarks that pair an image with accompanying clinical text, multimodal foundation models score well primarily by leveraging the text rather than analyzing the image.
arXiv preprint arXiv:2311.05591, Nov 2024